Abstract
For many music analysis problems, we need to know the presence of instruments for each time frame in a multi-instrument musical piece. However, such a frame-level instrument recognition task remains difficult, mainly due to the lack of labeled datasets. To address this issue, we present in this paper a large-scale dataset that contains synthetic polyphonic music with frame-level pitch and instrument labels. Moreover, we propose a simple yet novel network architecture to jointly predict the pitch and instrument for each frame. With this multitask learning method, the pitch information can be leveraged to predict the instruments, and also the other way around. And, by using the so-called pianoroll representation of music as the main target output of the model, our model also predicts the instruments that play each individual note event. We validate the effectiveness of the proposed method for framelevel instrument recognition by comparing it with its singletask ablated versions and three state-of-the-art methods. We also demonstrate the result of the proposed method for multipitch streaming with real-world music.
Musescore Dataset
In our tasks, we need a large-scale dataset which containing both instrument frame labels and multi-pitch labels. To our best knowledge, there is no such dataset existing now. As a result, we collect a large scale dataset from Musescore online community. This dataset containing variety of genre, sound of synthesizers and instrument categories. It also contains paired MIDI and MP3 files for each song. We process the MIDI files to instrument, pitch and piano roll labels. A main limitation of this dataset is that there is no singing voice. However, in the future, we can augment the data by mixing the singing voice with the songs in dataset. Another plan to improve this dataset is to re-synthesize MIDI files from Musescore dataset or add random velocity to produce more realistic sound. All the code for collecting and processing the dataset is shared on our Github.
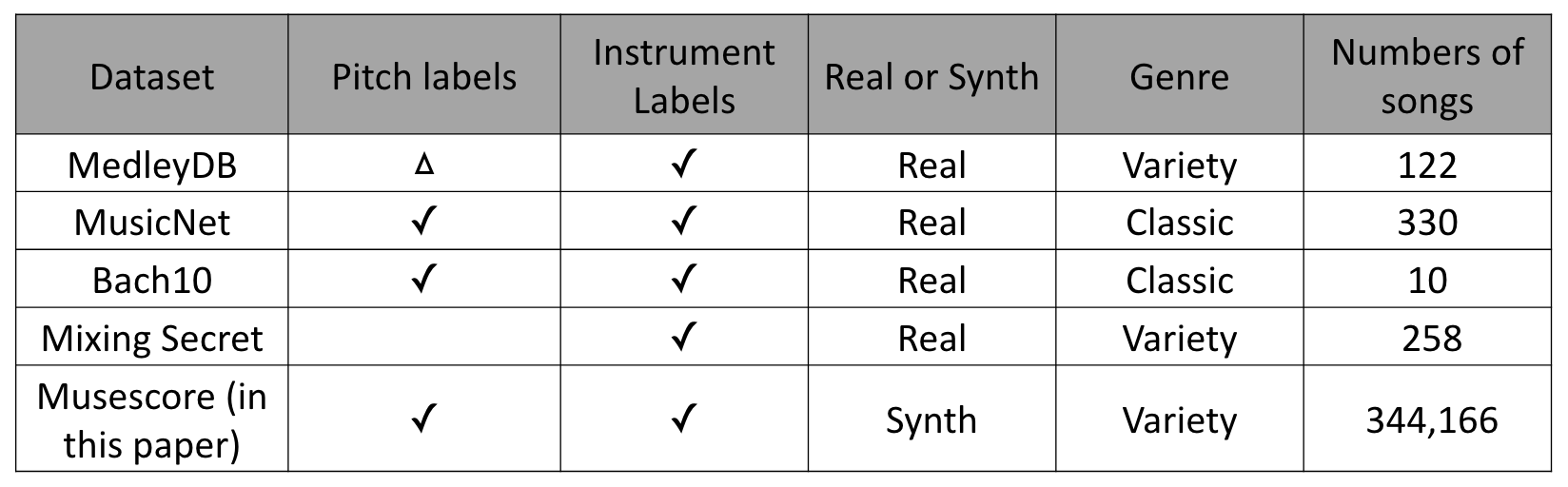
This table provides information regarding some datasets that provide frame-level labels for either pitch or instrument. (Triangle denote ‘part of it’)
Proposed Model
Input Feature
We use CQT [24] to represent the input audio, since it adoptsa log frequency scale that better aligns with our perception of pitch. We compute CQT by librosa [25], with 16 kHz sampling rate, 512-sample hop size, and 88 frequency bins. For the convenience of training with mini-batches, each audio clip in the training set is divided into 10-second segments.
Output Feature
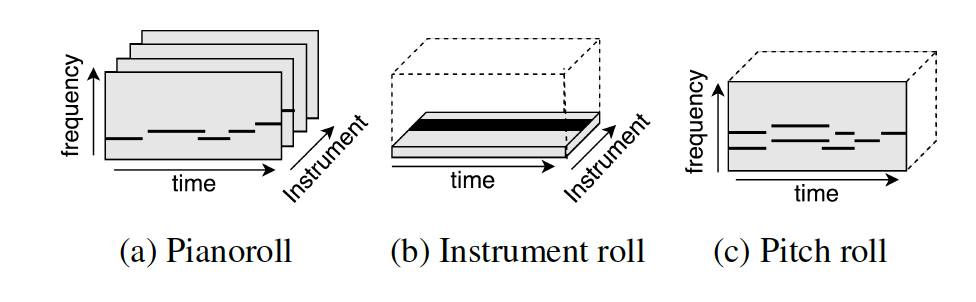
We train a multitask learning model to predict pianoroll, instrument frame labels, and multi-pitch labels at the same time. Since pianoroll is a three dimensional representation, instrument labels can be derieved by summing up accross pitch dimension. Pitch labels can also be derieved by summing up accross instrument dimension.
Model Structure
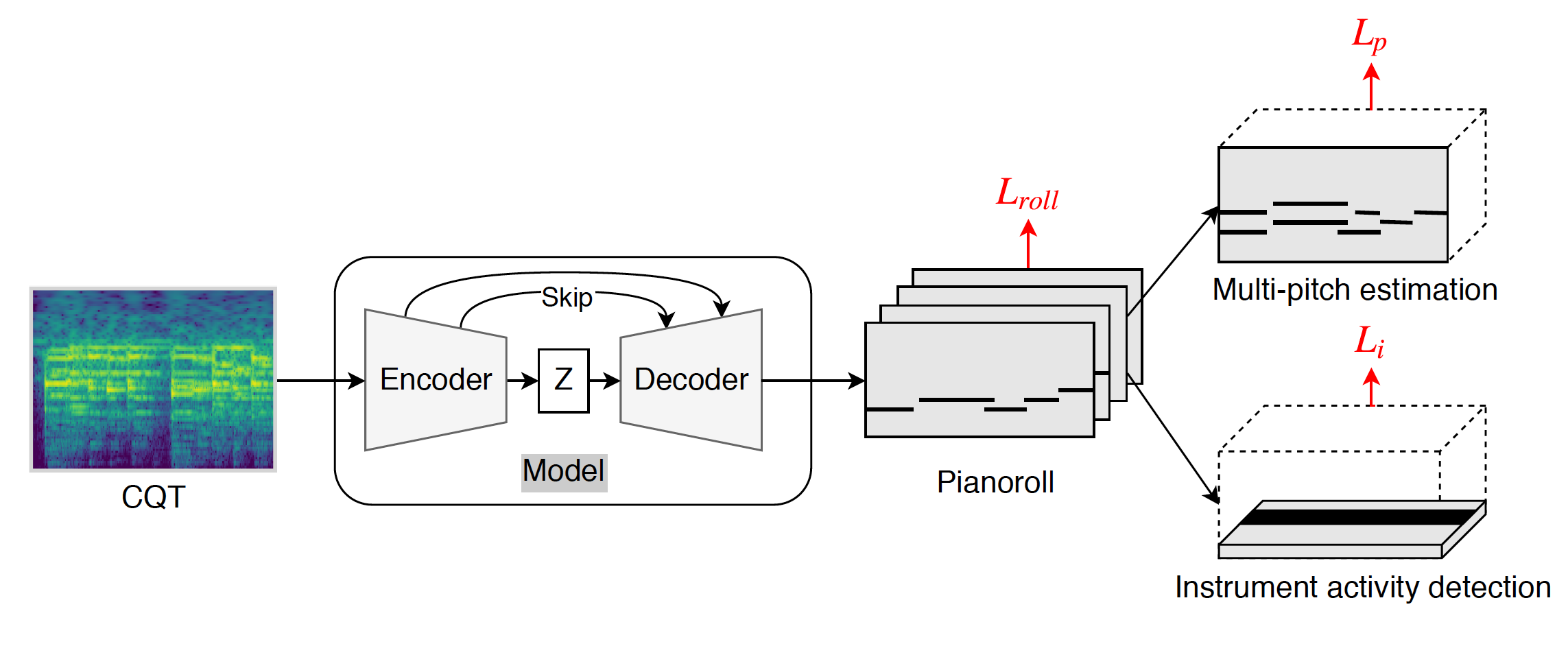
The network architecture is a simple convolutional encoder/decoder network with symmetric skip connections between the encoding and decoding layers. Such a “U-net” structure has been found useful for image segmentation [23], where the task is to learn a mapping function between a dense, numeric matrix (i.e., an image) and a sparse, binary matrix (i.e., the segment boundaries). We presume that the U-net structure can work well for predicting the pianorolls, since it also involves learning such a mapping function. In our implementation, the encoder and decoder are composed of four residual blocks for convolution and up-convolution. Each residual block has three convolution, two atchNorm and two leakyReLU layers. The model is trained with stochastic gradient descent with 0.005 learning rate.
Loss Function
We train the model by using three cost functions, Lroll, Lp and Li, as shown in the above figure. For each of them, we use the binary cross entropy (BCE) between the groundtruth and the predicted matrices (tensors). The BCE is defined as:
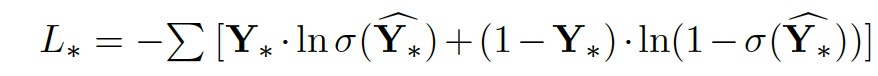
Result
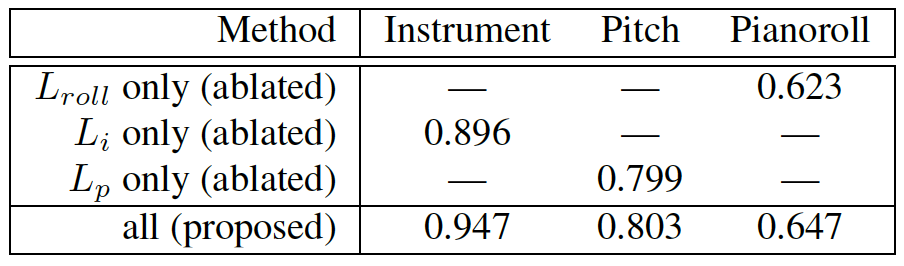
In this experiment, we compare the proposed multitask learning method with its single-task versions, using two non-overlapping subsets of MuseScore as the training and test sets. Specifically, we consider only the 9 most popular instruments (1Piano, acoustic guitar, electric guitar, trumpet, sax, violin, cello and flute) and run a script to pick for each instrument 5,500 clips as the training set and 200 clips as the test set. We consider three ablated versions here: using the U-net architecutre to predict only pianoroll (i.e. only Lroll), only instrument labels (i.e. only Li) and only pitch labels (i.e. only Lpitch).
Result shown in Table 2 clearly demonstrates the superiority of the proposed multitask learning method over the singletask counterparts, especially for instrument prediction. Here, we use mir eval [27] to calculate the ‘pitch’ and ‘pianoroll’ accuracies. For ‘instrument’, we report the F1-score.
[1] Jen-Yu Liu, Yi-Hsuan Yang, and Shyh-Kang Jeng,“Weakly-supervised visual instrument-playing action detection in videos,” IEEE Trans. Multimedia , in press.
[2] Siddharth Gururani, Cameron Summers, and Alexander Lerch, “Instrument activity detection in polyphonic music using deep neural networks,” in Proc. ISMIR, 2018.
[3] Yun-Ning Hung and Yi-Hsuan Yang, “Frame-level instrument recognition by timbre and pitch,” in Proc. ISMIR ,2018, pp. 135–142.
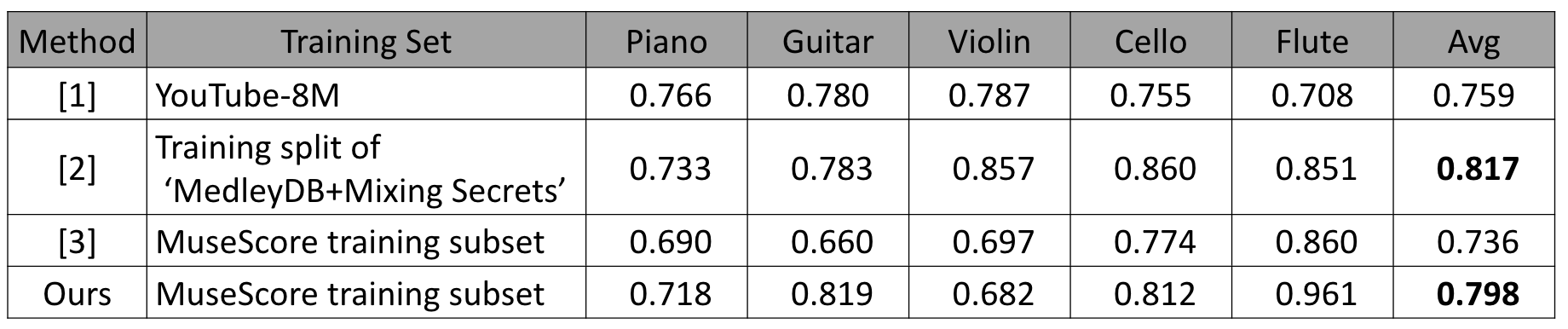
In the second experiment, we compare our method with three existing methods [1, 2, 3]. Following [2], we take 15 songs from MedleyDB and 54 songs from Mixing Secret as the test set, and consider only 5 instruments. The test clips contain instruments (e.g., singing voice) that are beyond these five. We evaluate the result for per-second instrument recognition in terms of area under the curve (AUC).
As shown in the above table, these methods use different training sets. Specifically, we retrain model [3] using the same training subset of MuseScore as the proposed model. The model [1] is trained on the YouTube-8M dataset. The model [2] is trained on a training split of ‘MedleyDB+Mixing Secret with 100 songs from each of the two datasets. The model [2] therefore has some advantages since the training set is close to the test set. The result of [1] and [2] are from the authors of the respective papers.
Table shows that our model outperforms the two prior arts [1,3] and is behind model [2]. We consider our model compares favorably with [13], as our training set is quite different from the test set. Interestingly, our model is better at the flute, while [2] is better at the violin. This might be related to the difference between the real and synthesized sounds for these instruments, but future work is needed to clarify.
Demo
We provide three kinds of demo so that the readers can play around our model!Here we provide a website to demo instrument activity detection for some songs we choose.
For thoses who are interested in our piano roll prediction result, we provide a demo website on some songs we choose.
For thoses who are interested in our piano roll prediction result and want to try on their own music, we provide a demo website to let you play around our model! Just to warn that so far our model cannot perform very well on the song with singing voice. Hope you will like it!